 Experiments - Beta
Experiments - Beta
CONP Portal | About
The Canadian Open Neuroscience Platform (CONP) Portal is a web interface that facilitates open science for the neuroscience community by simplifying global access to and sharing of datasets and tools. The Portal internalizes the typical cycle of a research project, beginning with data acquisition, followed by data processing with published tools, and ultimately the publication of results with a link to the original dataset.
The CONP Portal was built using technologies and best practices that make sharing easier and reproducible. DataLad and Git-Annex are used to track and index datasets, while Boutiques is used in conjunction with a container engine (e.g. Docker or Singularity) to ensure reproducibility of results. In addition, some pipelines can also be run using High Performance Computing (HPC) via links to the CBRAIN platform.
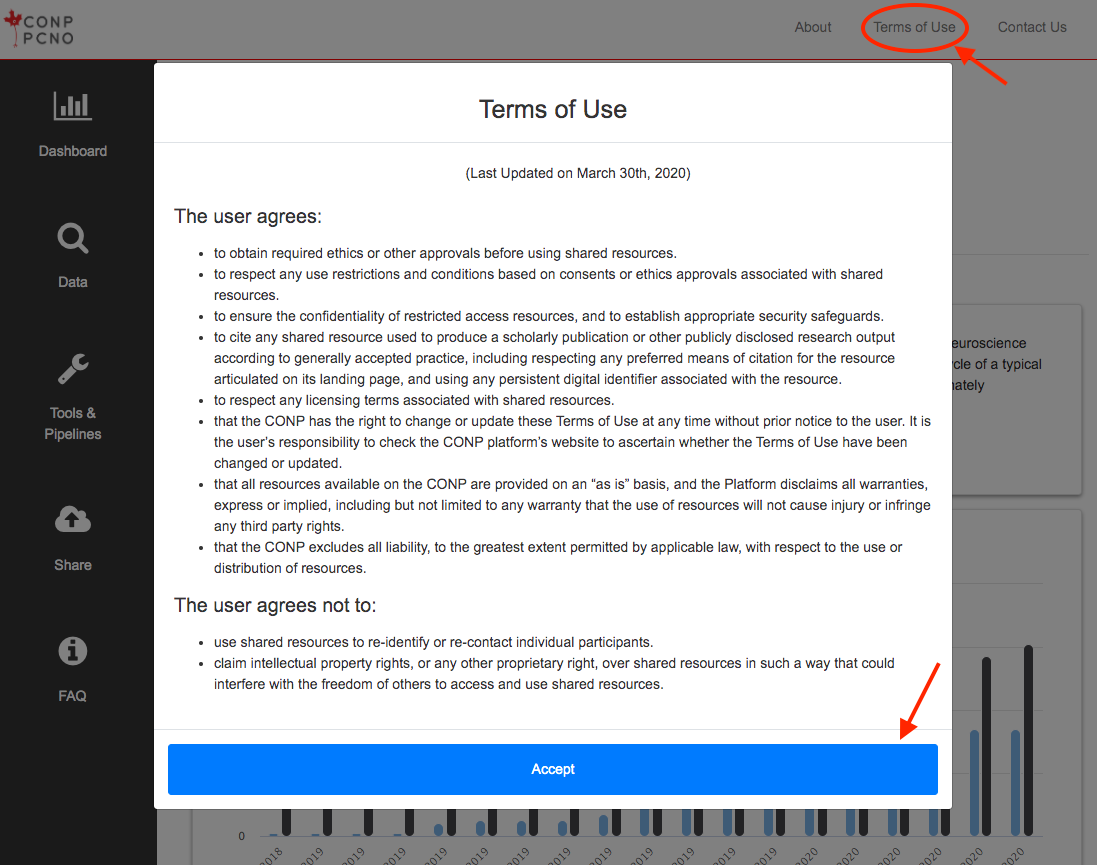
A tutorial on how to use the CONP Portal can be found here.
What are the Portal features?
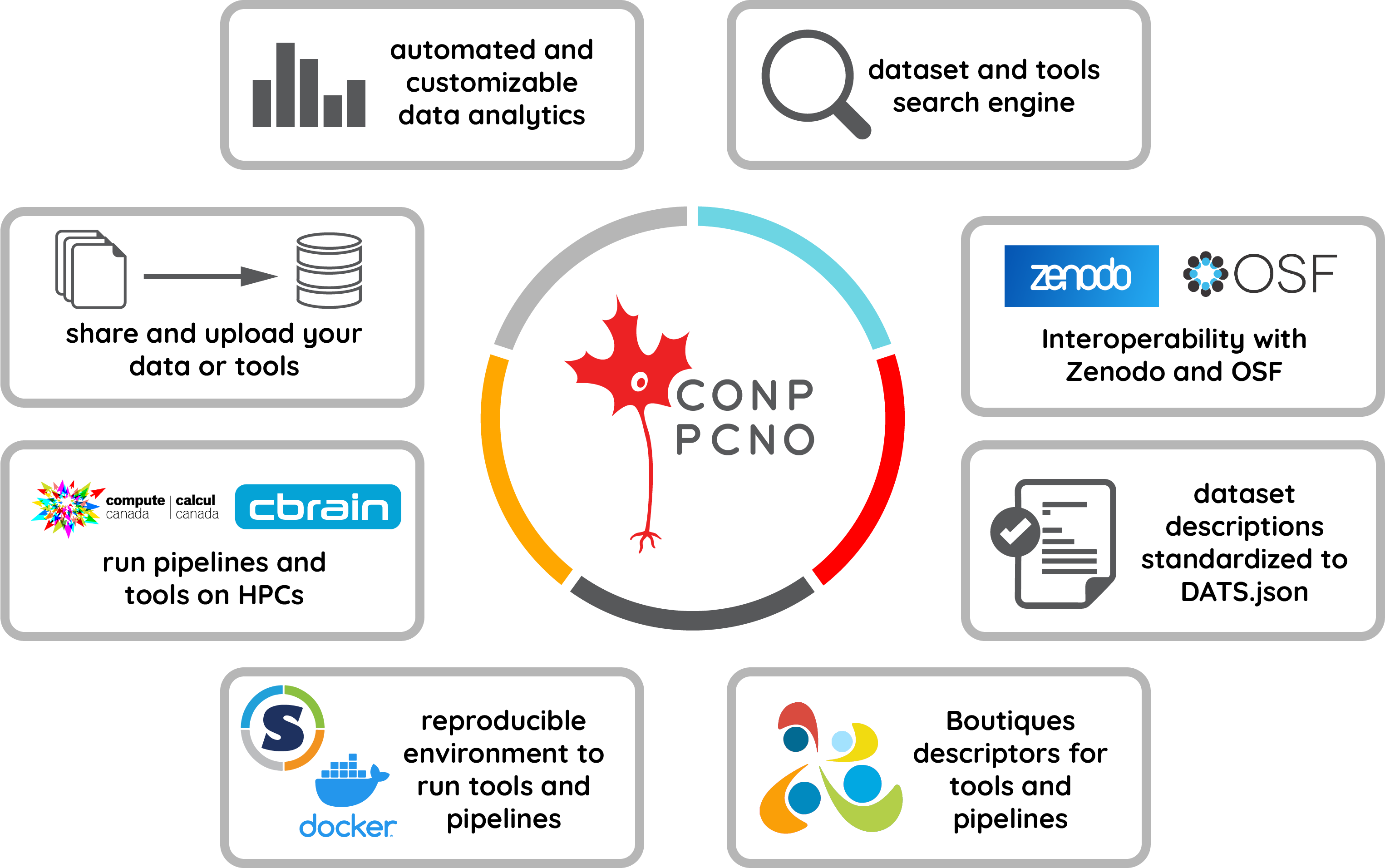
The CONP Portal offers:
- dataset and tool search engines
- detailed dataset descriptions in the form of a DATS.json file (based on schema.org)
- a web-based interface to facilitate the creation of the dataset descriptor (DATS.json)
- streamlined data download capabilities
- advanced dataset querying with Nexus
- a dashboard representation of CONP Portal content and activities
Among a number of upcoming features, we are working on integrating citation capabilities and the publishing of Notebooks via Neurolibre.
What kinds of data can I find on the CONP Portal?
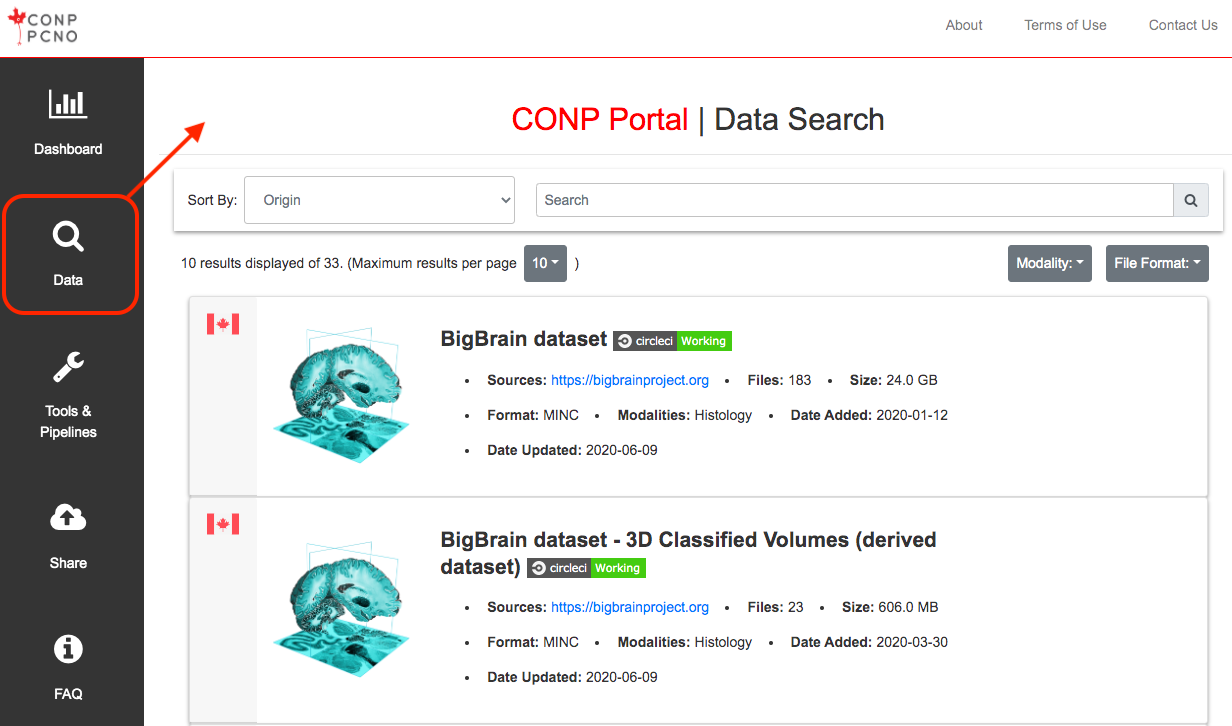
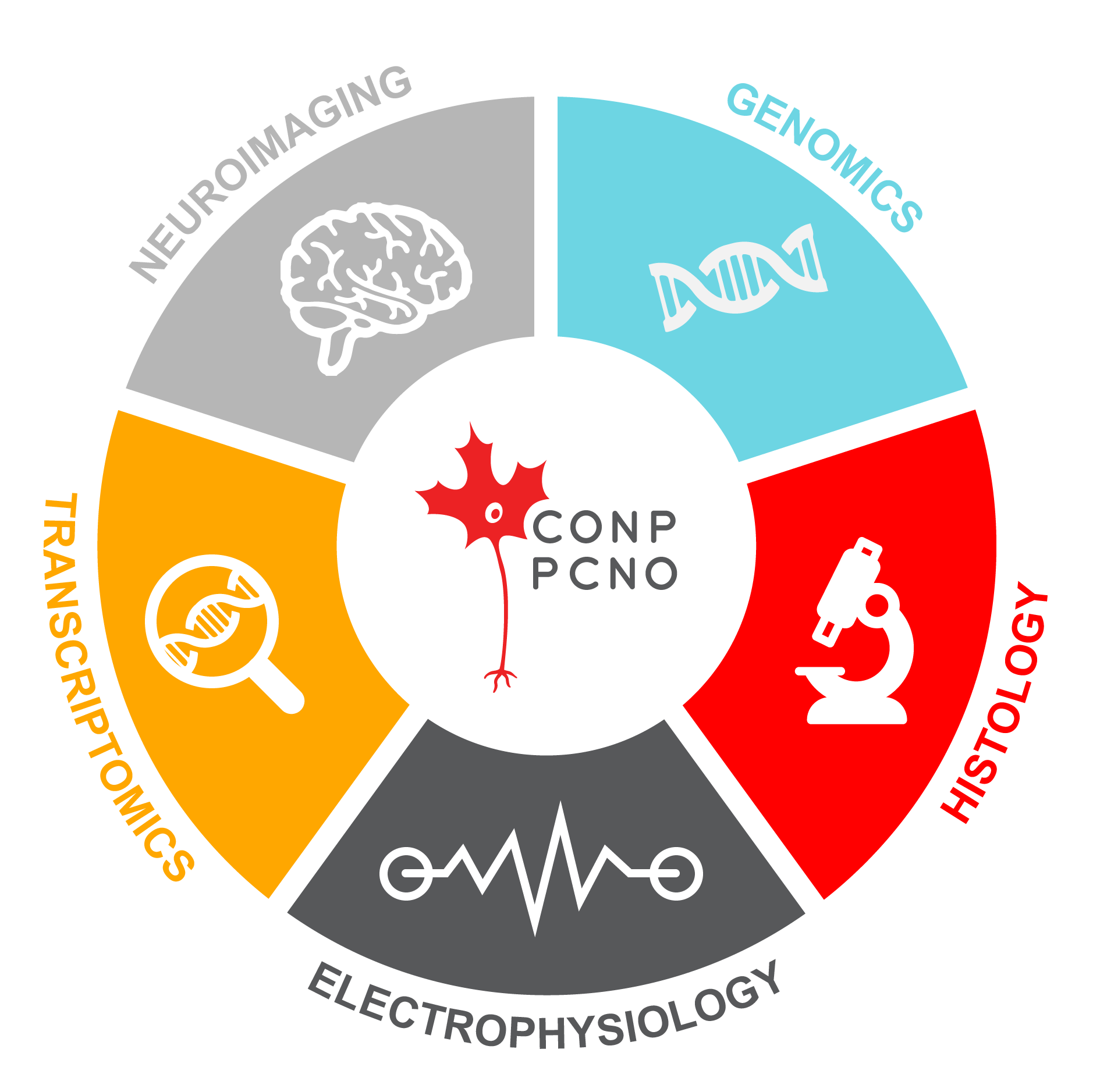
The CONP Portal provides a gateway to a diverse range of approximately 208 datasets including neuroimaging, histology, electrophysiology, transcriptomics, genomics, and many other data modalities. Many of these datasets have been provided by neuroscience research institutes across Canada, while others link to publicly available resources that may be of interest to neuroscientists. A full list can be found here.
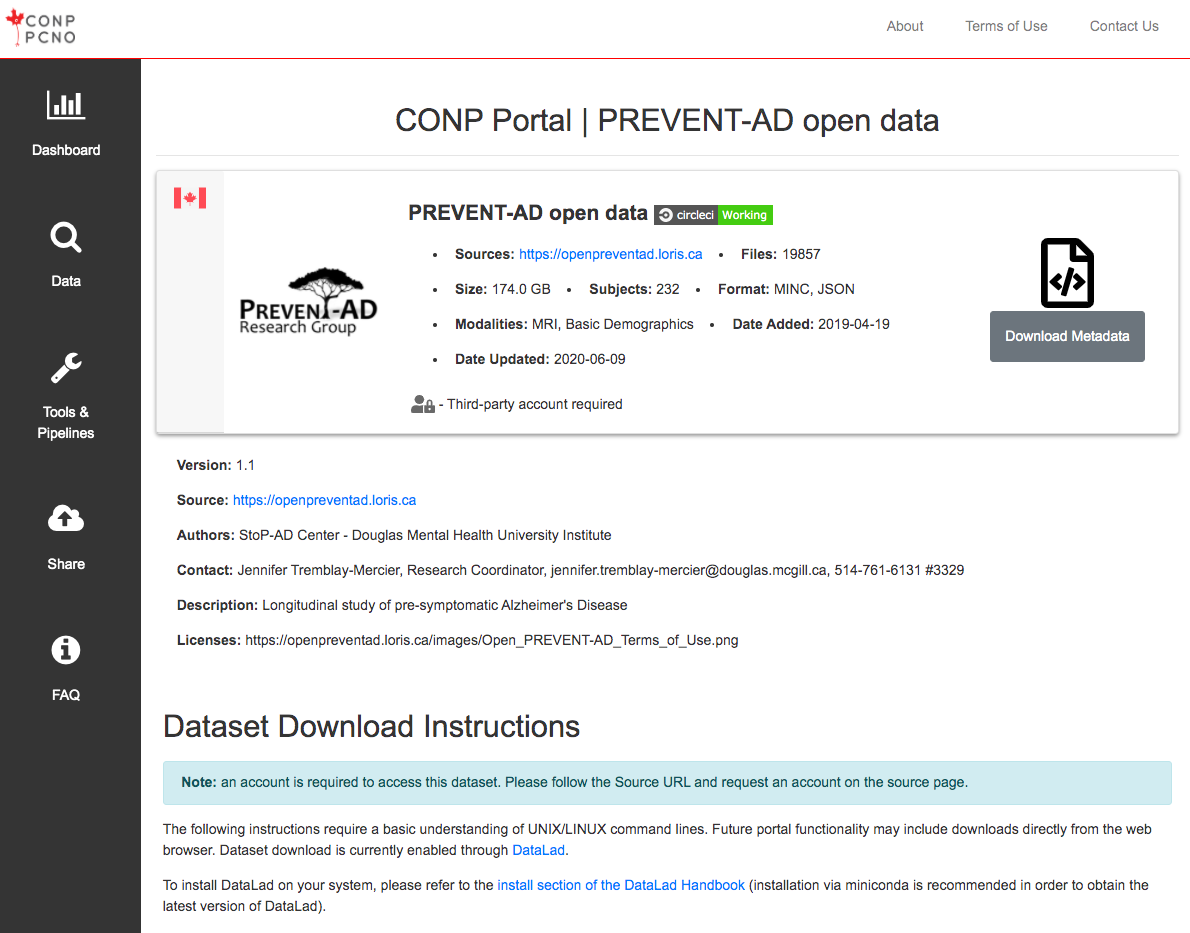
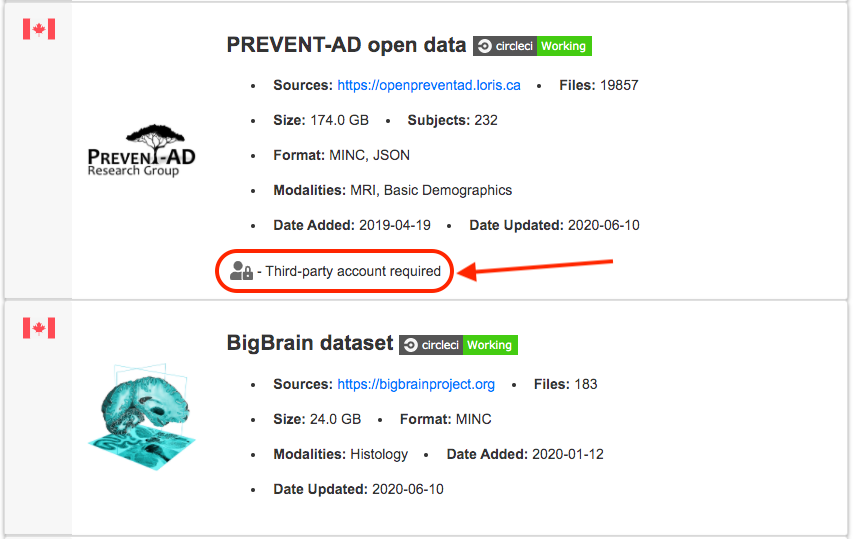
Among them, for instance, are the Pre-symptomatic Evaluation of Experimental or Novel Treatments for Alzheimer Disease (PREVENT-AD) datasets. They include longitudinal MRI scans and basic demographics for over 300 individuals with a family history of Alzheimer's Disease. In addition, more sensitive data are also available to Principal Investigators through a registered-access database of the PREVENT-AD dataset. These registered-access data include clinical and cognitive measures, as well as CSF protein levels and other biomarkers.
How can I access datasets?
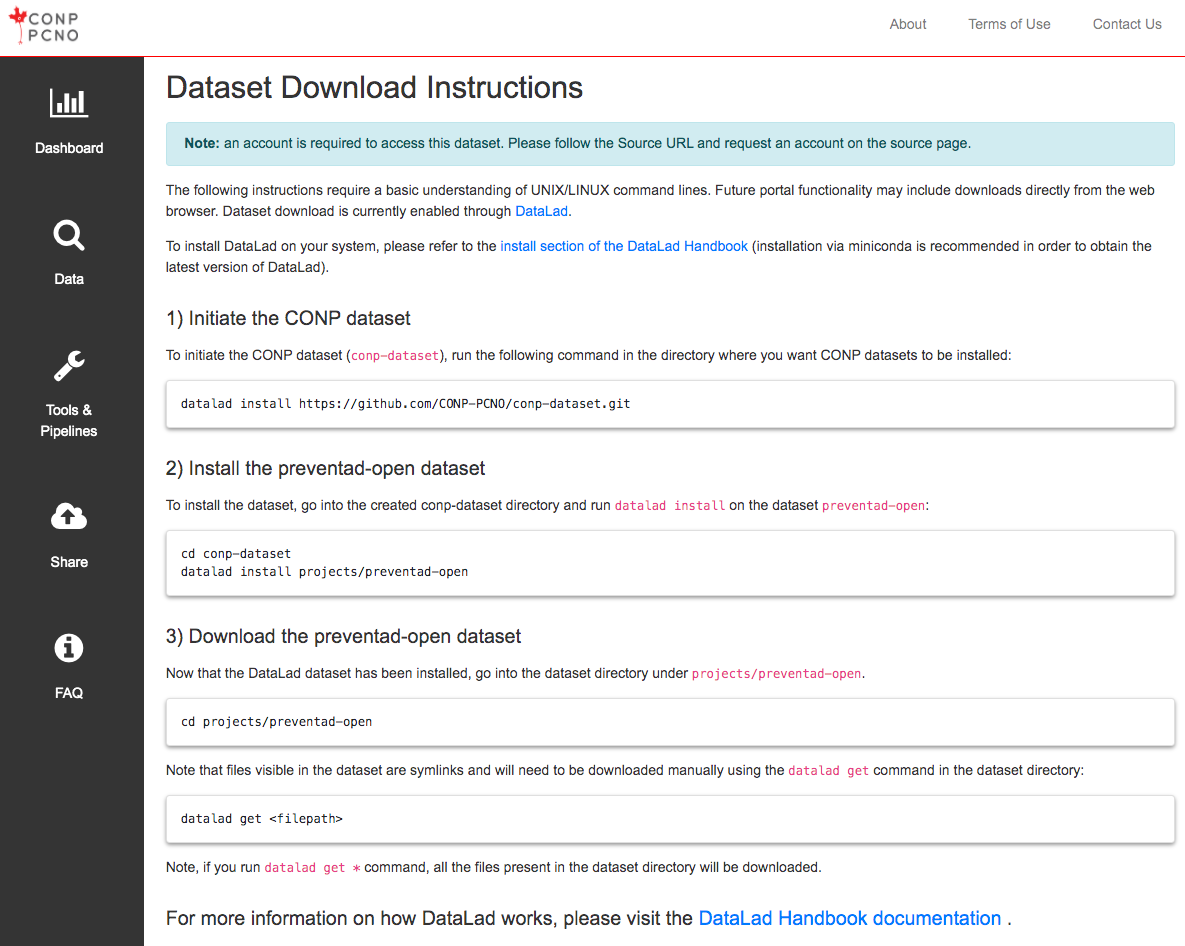
The CONP Portal was designed to parse existing datasets from both external and internal sources, allowing it to provide access to a very wide variety of data. To access data, the user will first go to the Data Search page and filter for data of interest by keyword in the search box. Clicking on an individual dataset among the search results will provide more detailed information and download instructions. Depending on the dataset, data download may be available through both the DataLad data management system and a one-click direct download function.
The CONP Portal allows you to access and process data on both public and private infrastructures. The ownership of all data uploaded and stored on the CONP Portal is retained by the original owner, along with all copyright and license attributes.
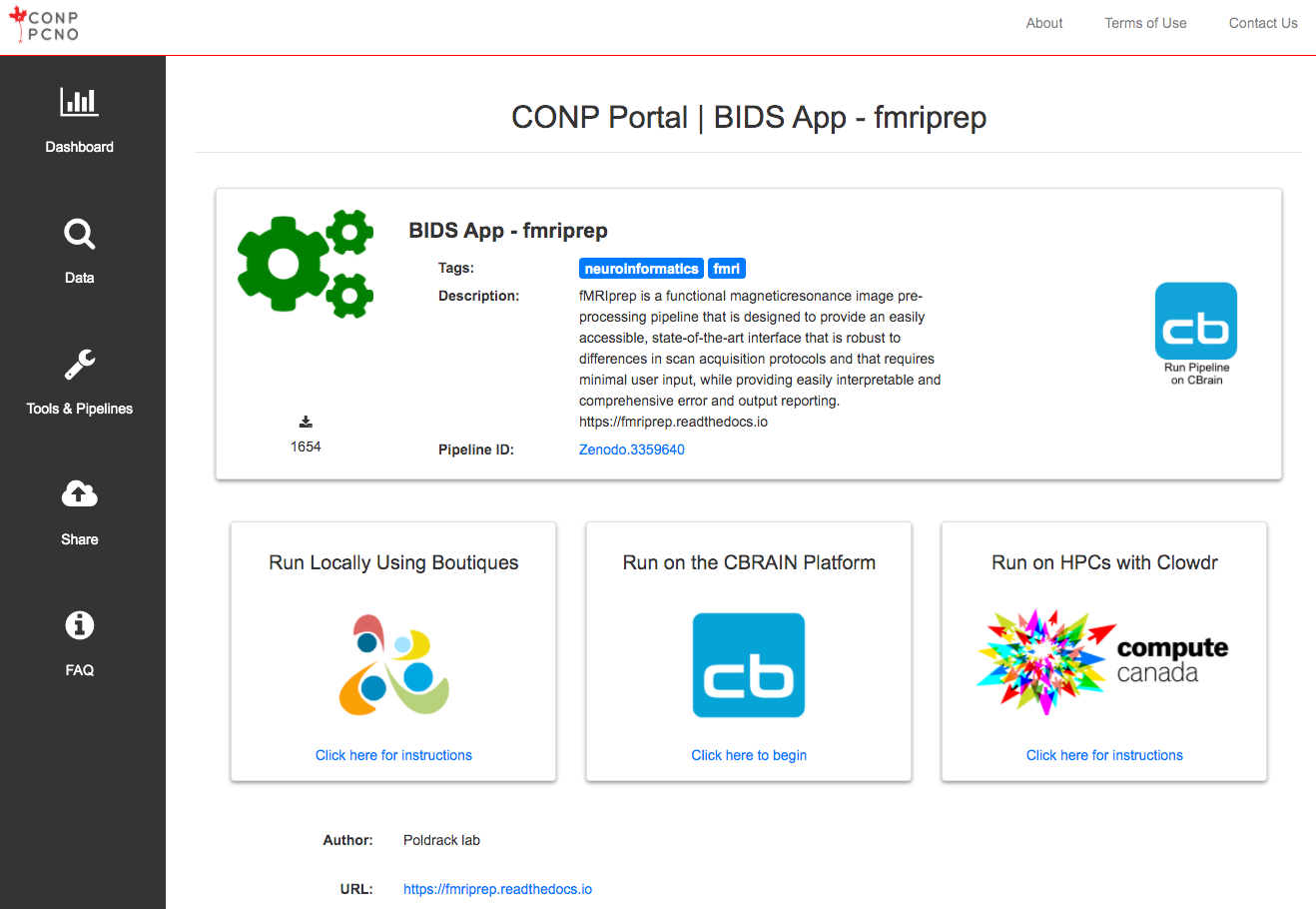
Once a dataset has been chosen, we also provide a wide range of tools and pipelines with which to process them. Read the following sections to find out more.
What tool/pipelines are accessible via the CONP Portal?
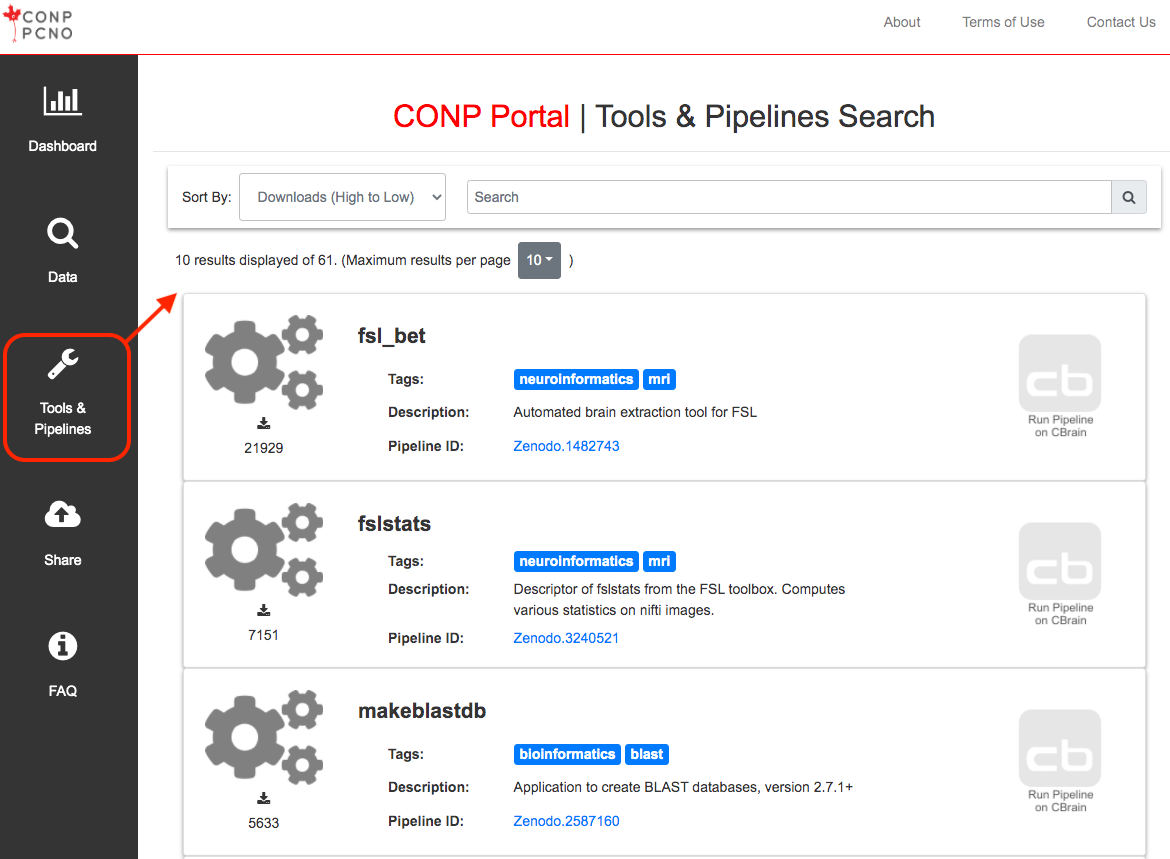
The CONP Portal aggregates a diverse range of 154 tools and pipelines. Many of these are well-established and have been sourced from or provided by research institutes from around the world. A full list can be found here.
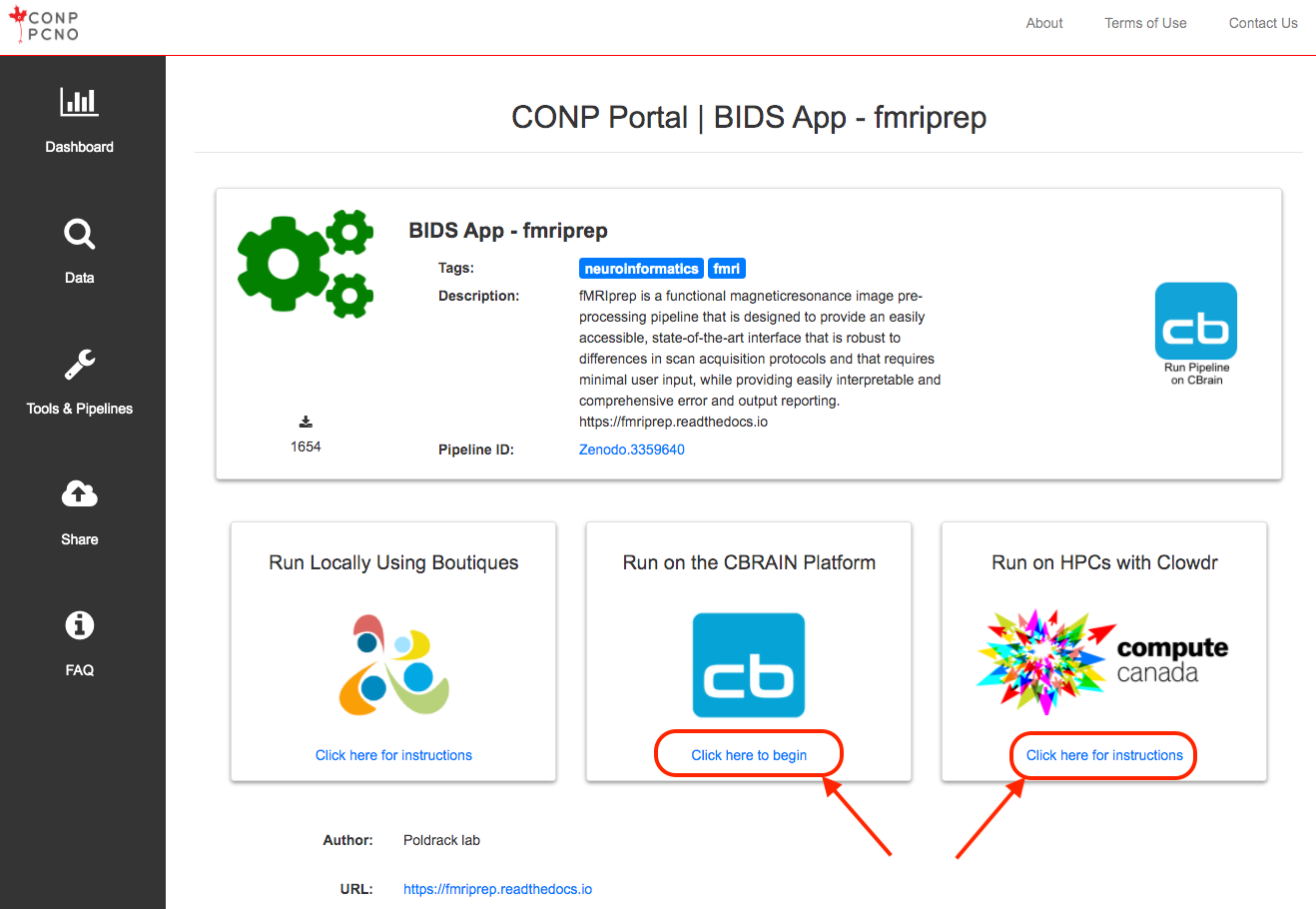
How can I use tools/pipelines?
Several mechanisms are available to run tools and pipelines found on the CONP Portal:
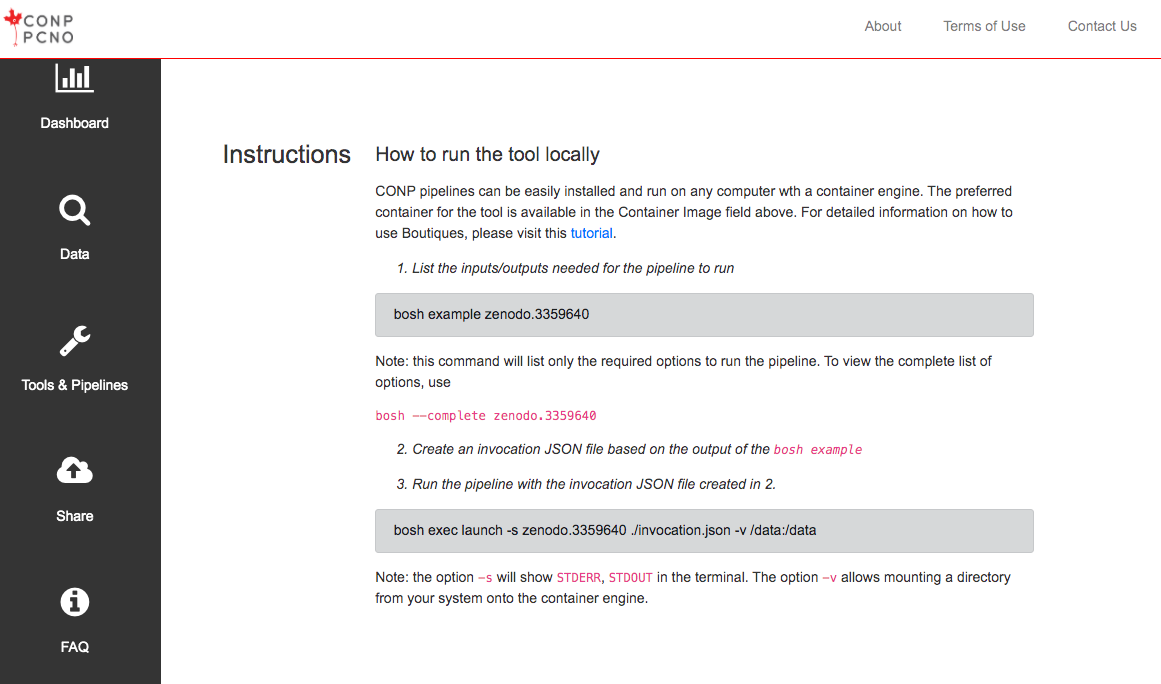
- locally on any system using Boutiques and a container engine (Docker or Singularity) based on the Zenodo ID of the tool. (If you have never used Boutiques in the past, we recommend the following this tutorial)
- on High Perfomance Computing infrastructure via CBRAIN or Clowdr
How can I share/upload a dataset?
The CONP Portal offers a distributed, automated, and simple manner for sharing data according to the FAIR principles, either through API connections to existing platforms or by providing resources to users who lack storage/sharing infrastructure.
Data can be uploaded to the CONP Portal via the following mechanisms (Detailed instructions are available for all these options):