 Experiments - Beta
Experiments - Beta
CONP Portal | Tutorial
The CONP Portal is a web interface developed by the Canadian Open Neuroscience Platform (CONP) to facilitate the sharing of datasets, analytical tools, and experiments.
How to access the Portal
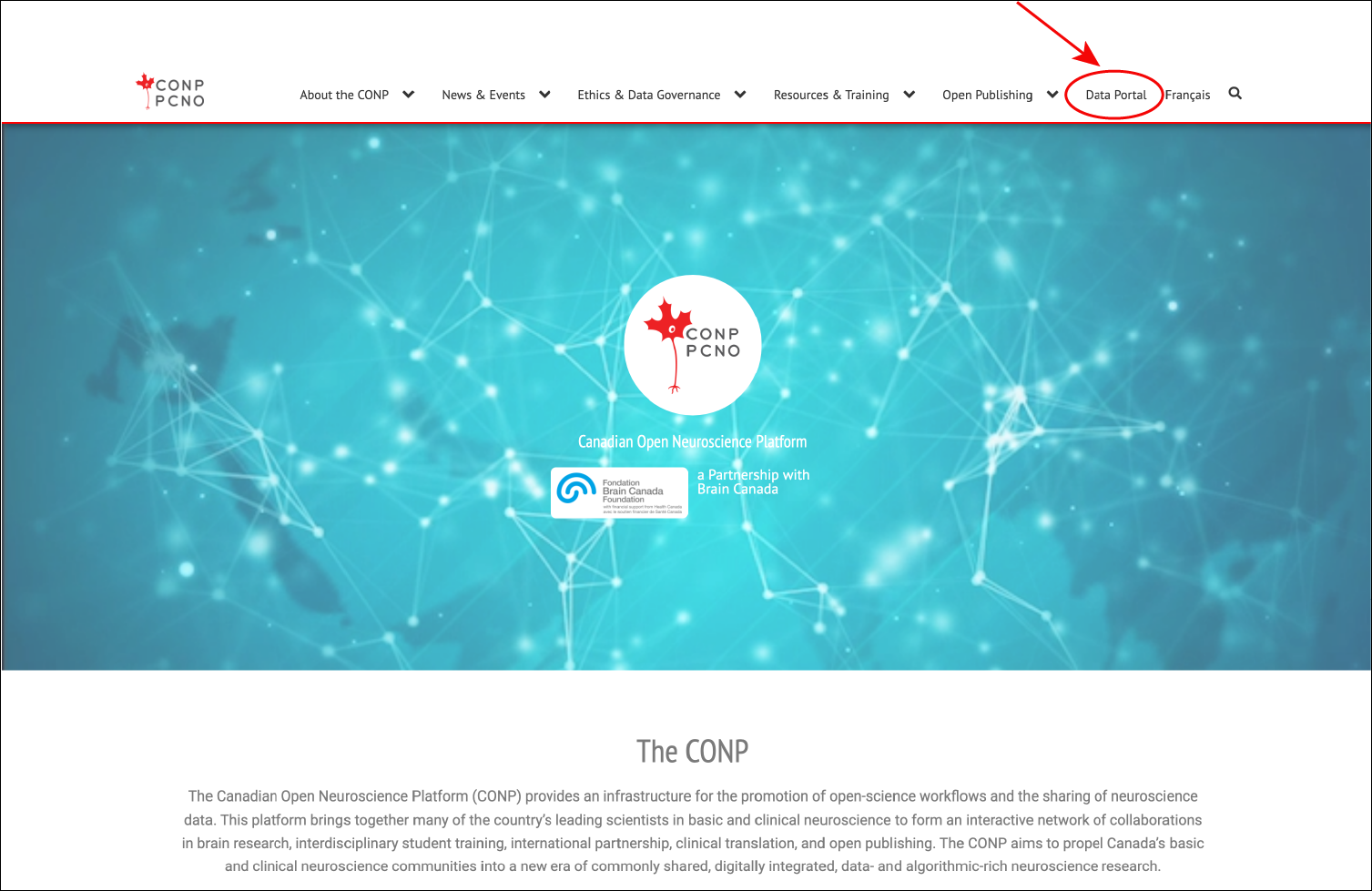
The CONP Portal is accessible via the Portal link at the top-right of the CONP's website or directly at portal.conp.ca.
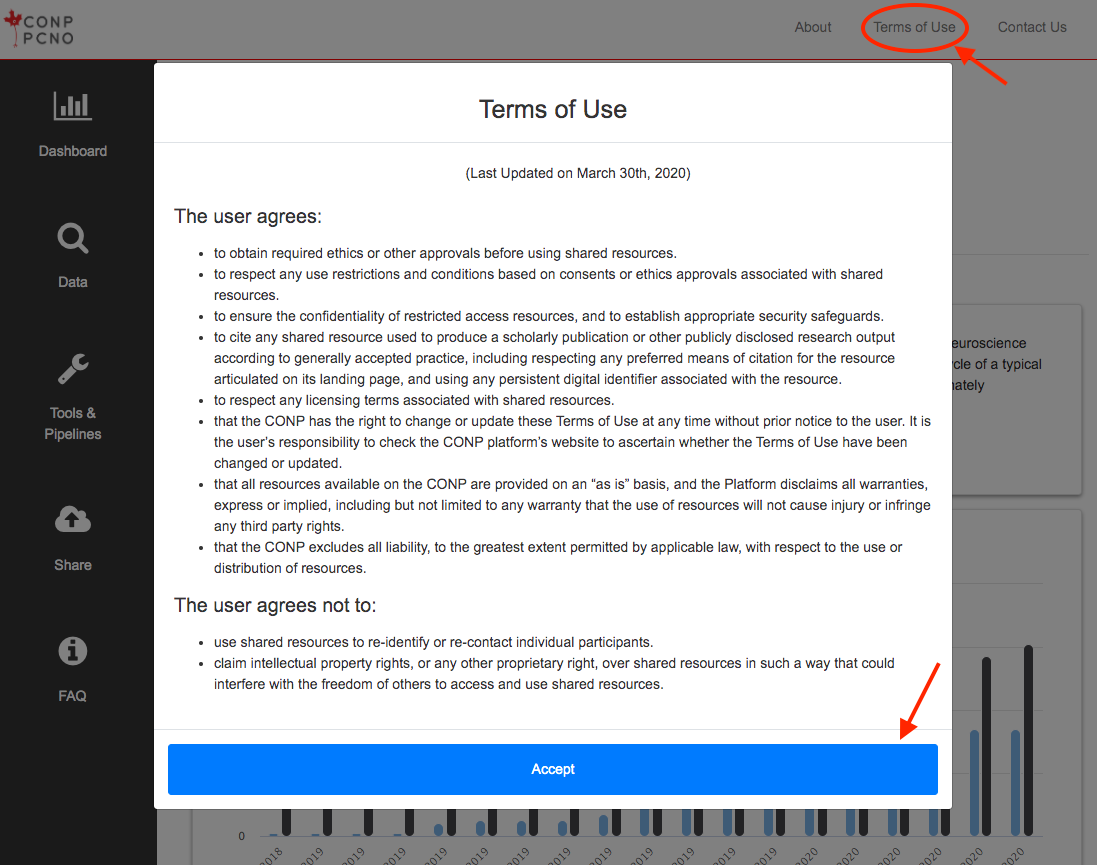
No login is required to access the CONP Portal but you will be asked to agree to its "Terms of Use" upon your first visit and these terms can always be accessed by clicking on the "Terms of Use" link at the top-right of the Portal page.
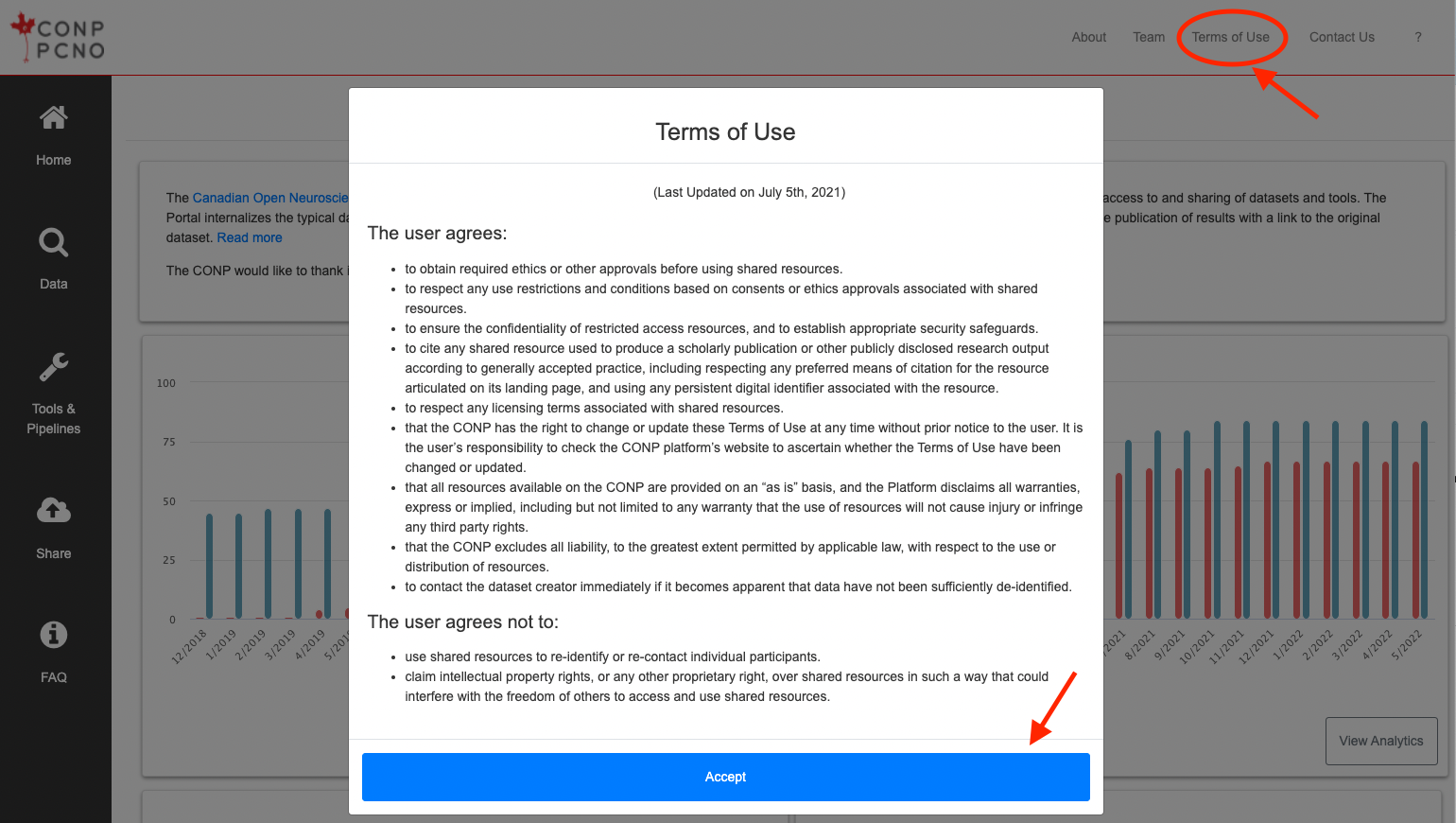
After agreeing to the Terms of Use (by clicking "Accept"), you can search through the Portal's many and varied datasets, pipelines and experiments with the help of their respective search pages.
How to find and download datasets
Finding datasets
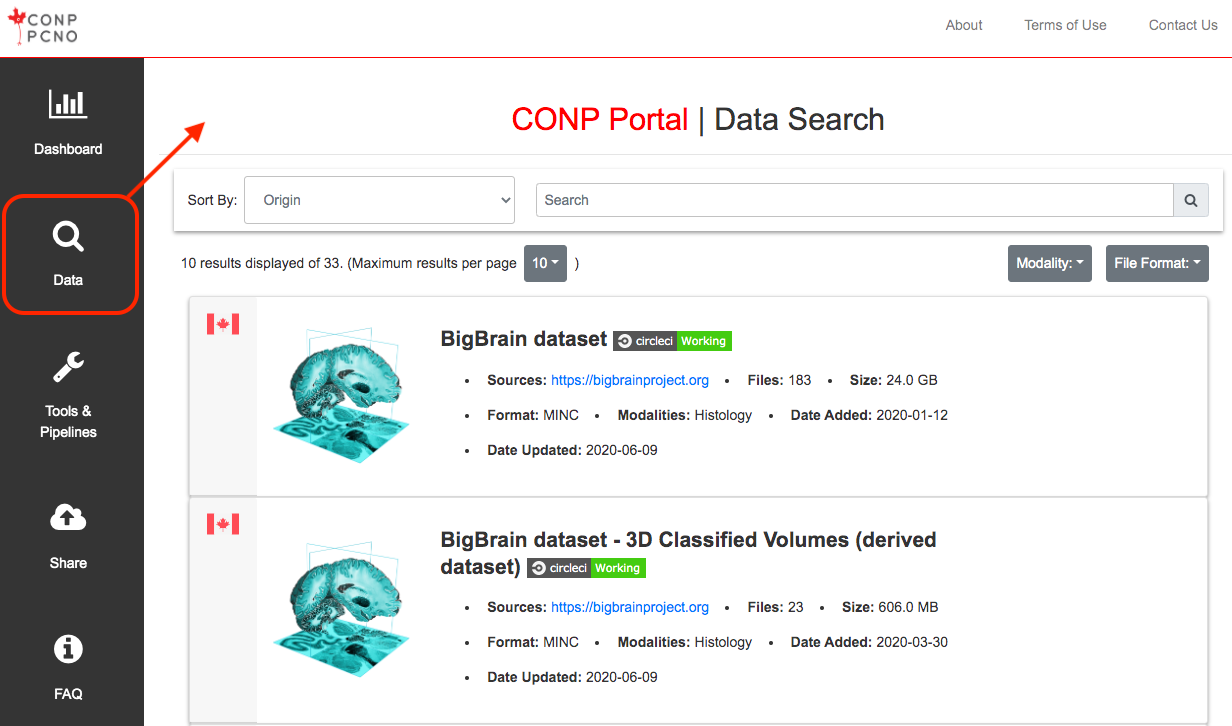
All datasets are listed in the Data search page of the CONP Portal.
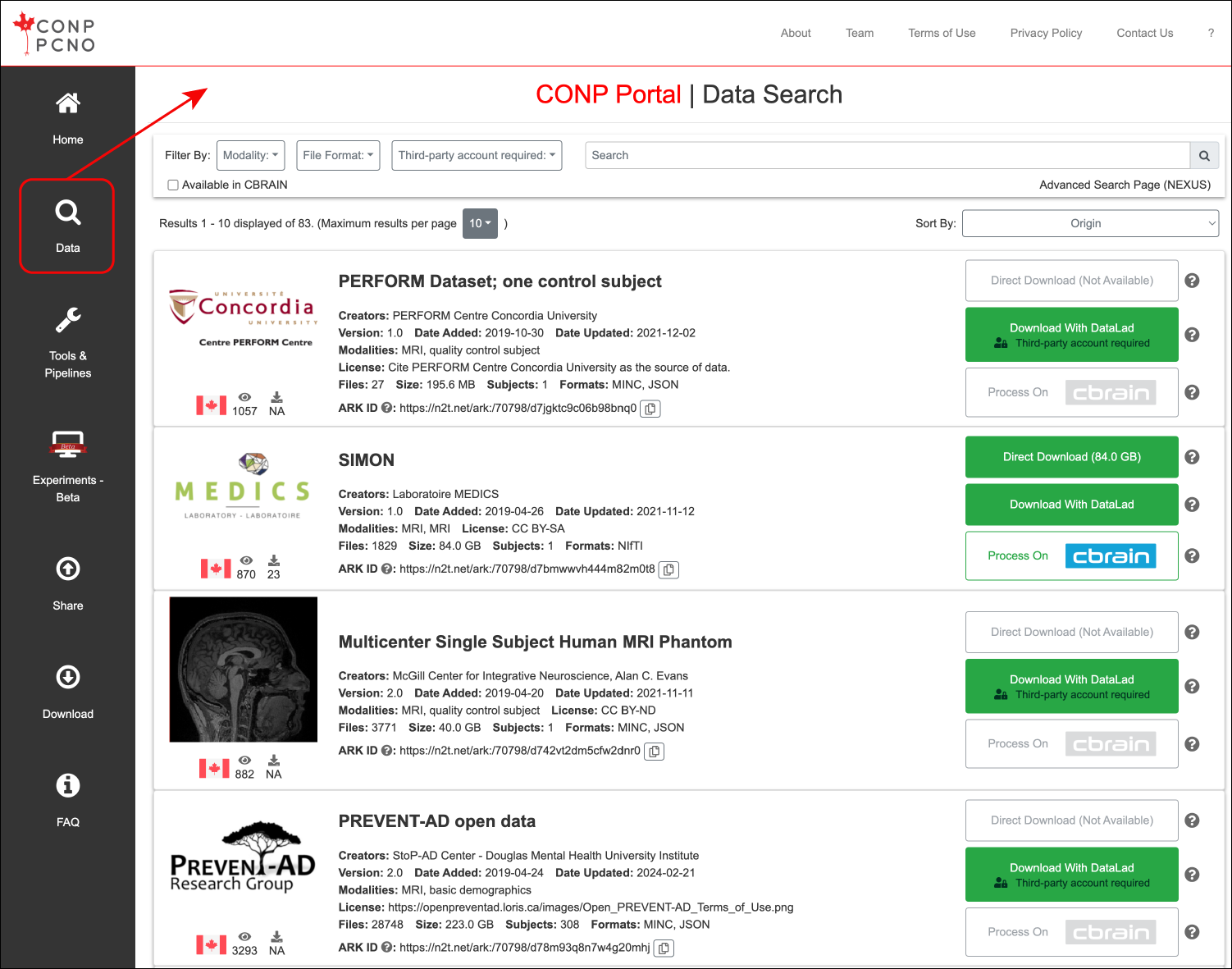
Search results display summary information for matching datasets and each can be expanded by clicking on its title to show further descriptions, including those in a 'README' provided by contributors. Shown below is part of the full page for the BigBrain dataset.
Downloading data
CONP Portal datasets exist under different access tiers:
- Some datasets are completely open and require no credentials. These are normally available through direct, browser-based download, through DataLad download, and are also directly available for processing on the CBRAIN platform, which provides browser-based access to High-Performance Computing infrastructure across Canada and internationally.
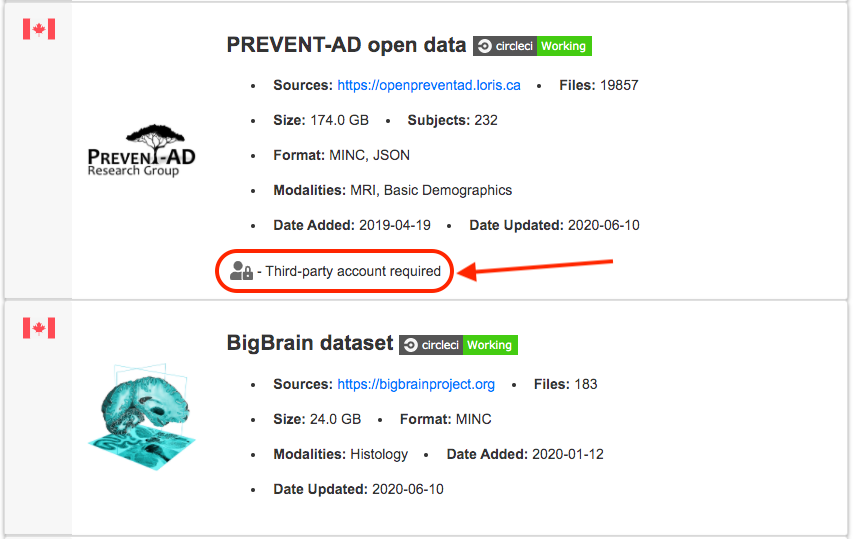
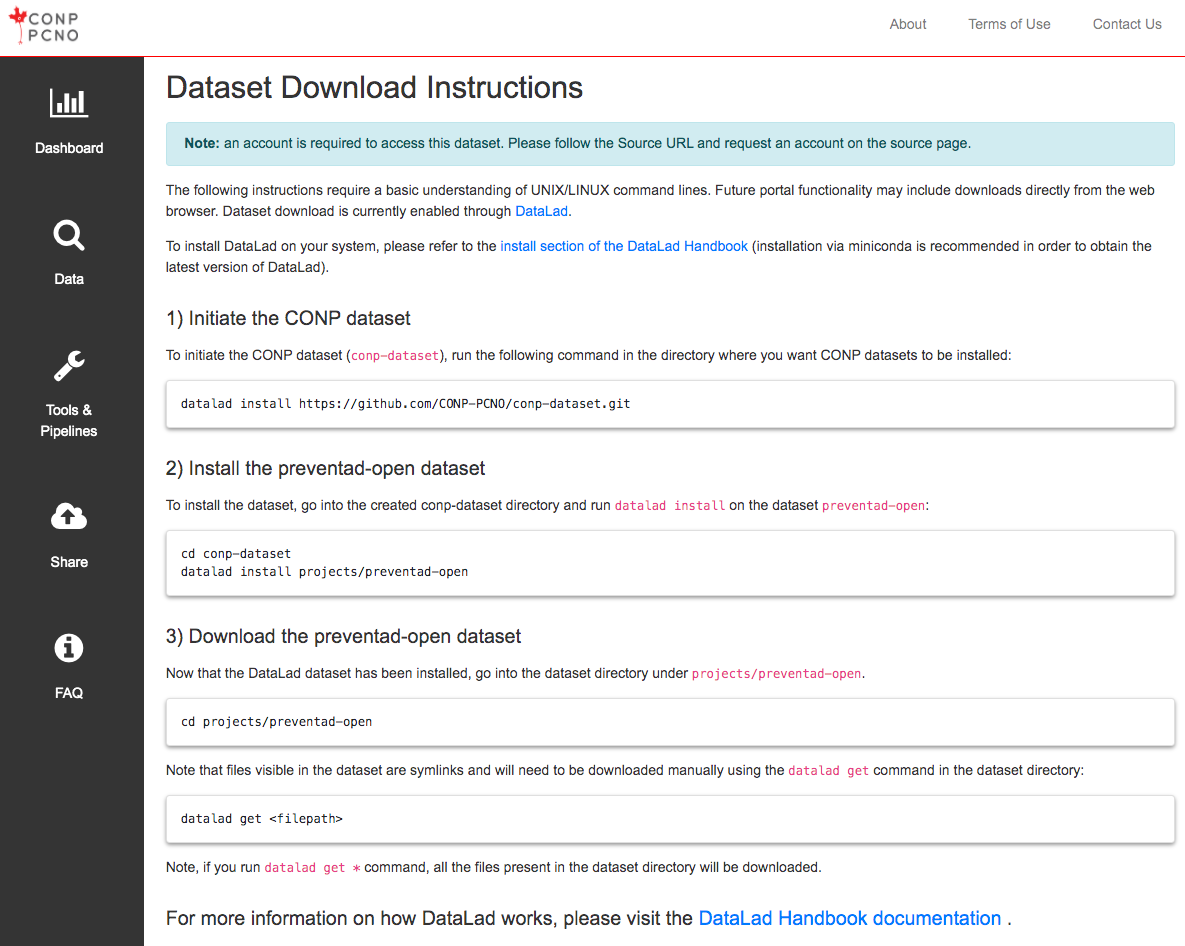
- Some datasets in the CONP Portal are under 'registered' access and require a third-party account. In such cases, instructions on how to obtain an account for those datasets will be displayed on the dataset's page.
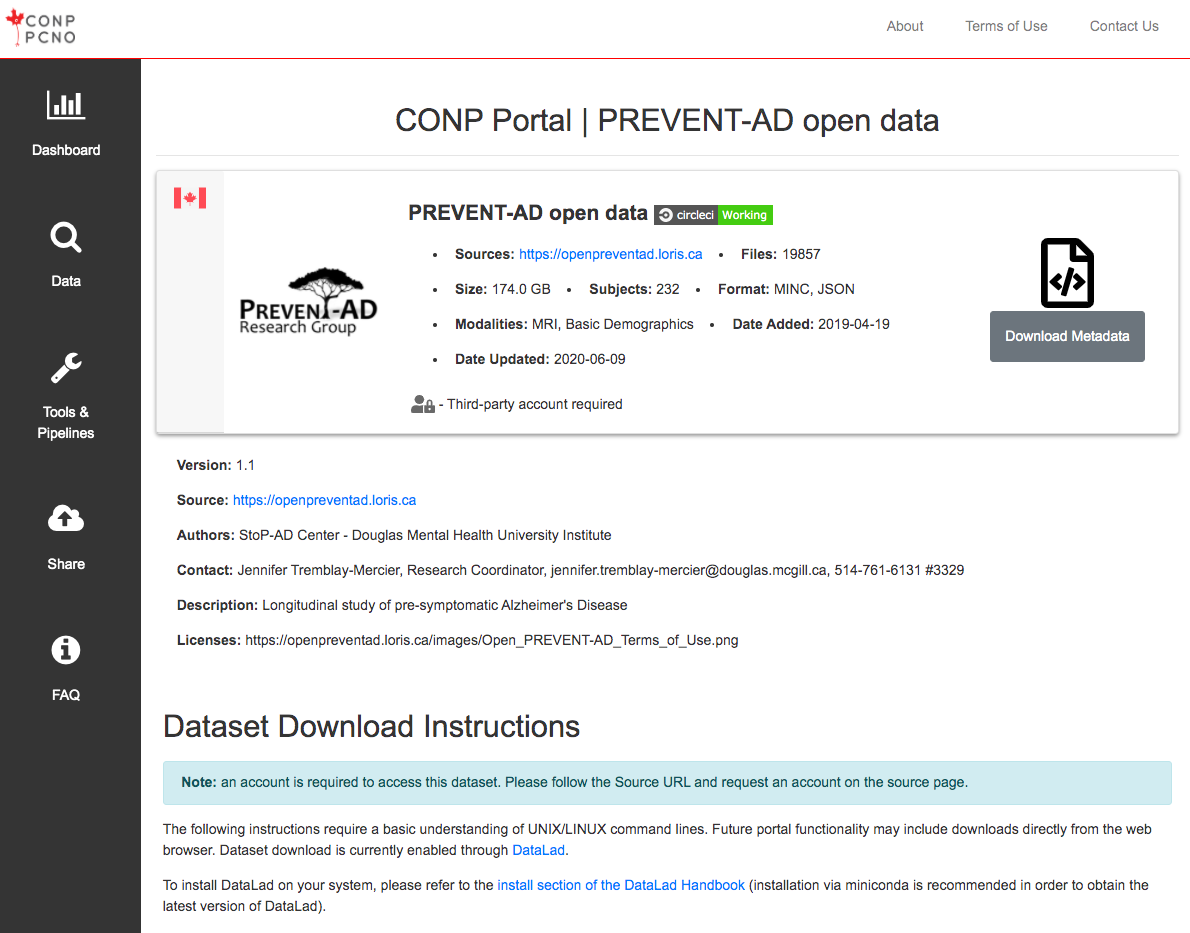
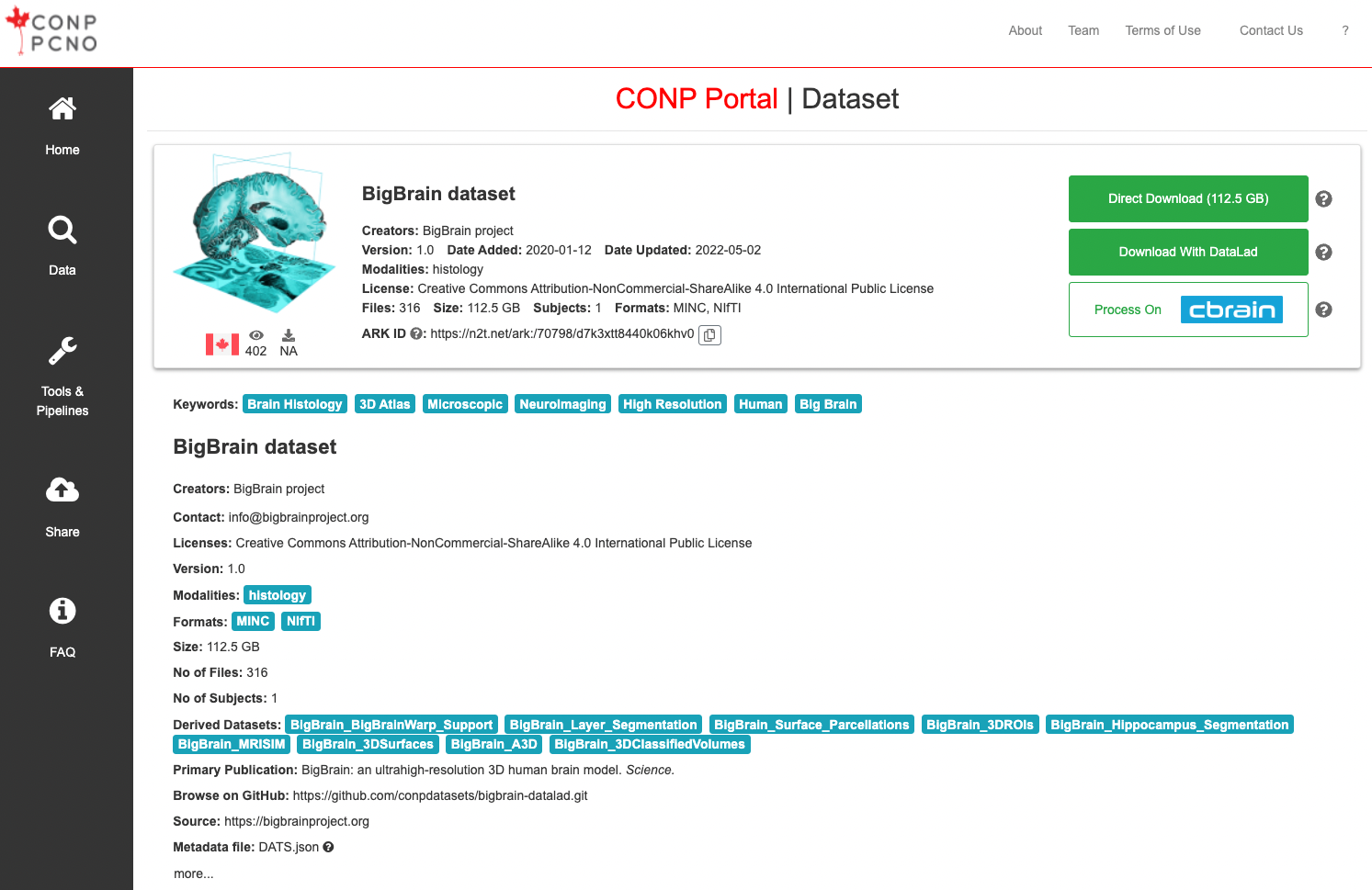
For example, below are two datasets, the open component of the PREVENT-AD dataset and the general BigBrain dataset:
- The first, the PREVENT-AD open dataset, requires a third-party account and can subsequently accessed through DataLad.
- The second, the BigBrain dataset, is completely open and does not require credentials to access. It is available through direct, browser-based download, through DataLad download, and is also directly available for processing on CBRAIN.

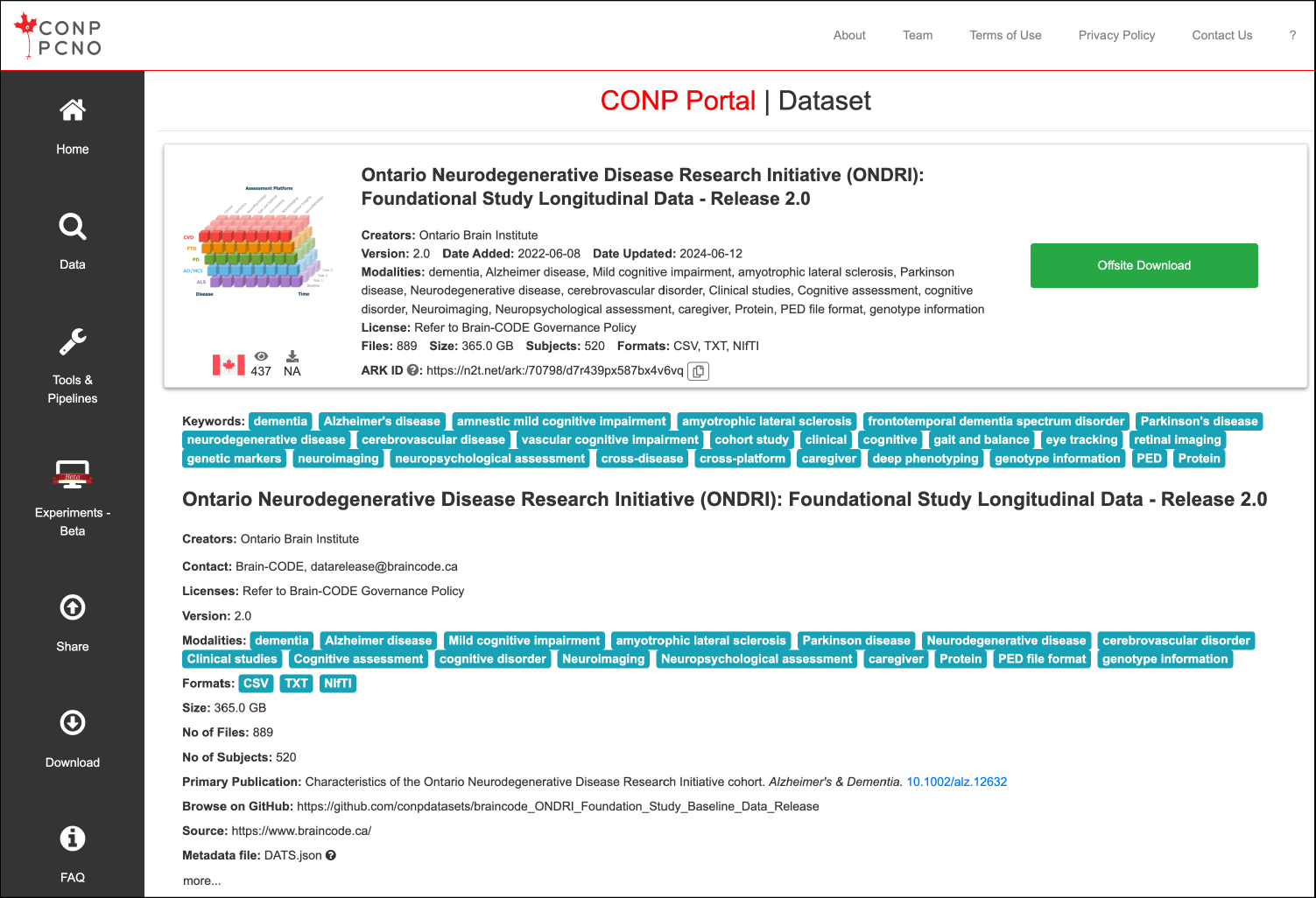
Other datasets still are under a controlled access model and can only be accessed by applying for credentials offsite. An example of this model is the Ontario Brain Institute dataset entitled Ontario Neurodegenerative Disease Research Initiative (ONDRI): Foundational Study Longitudinal Data - Release 2.0.
Finding and running tools/pipelines?
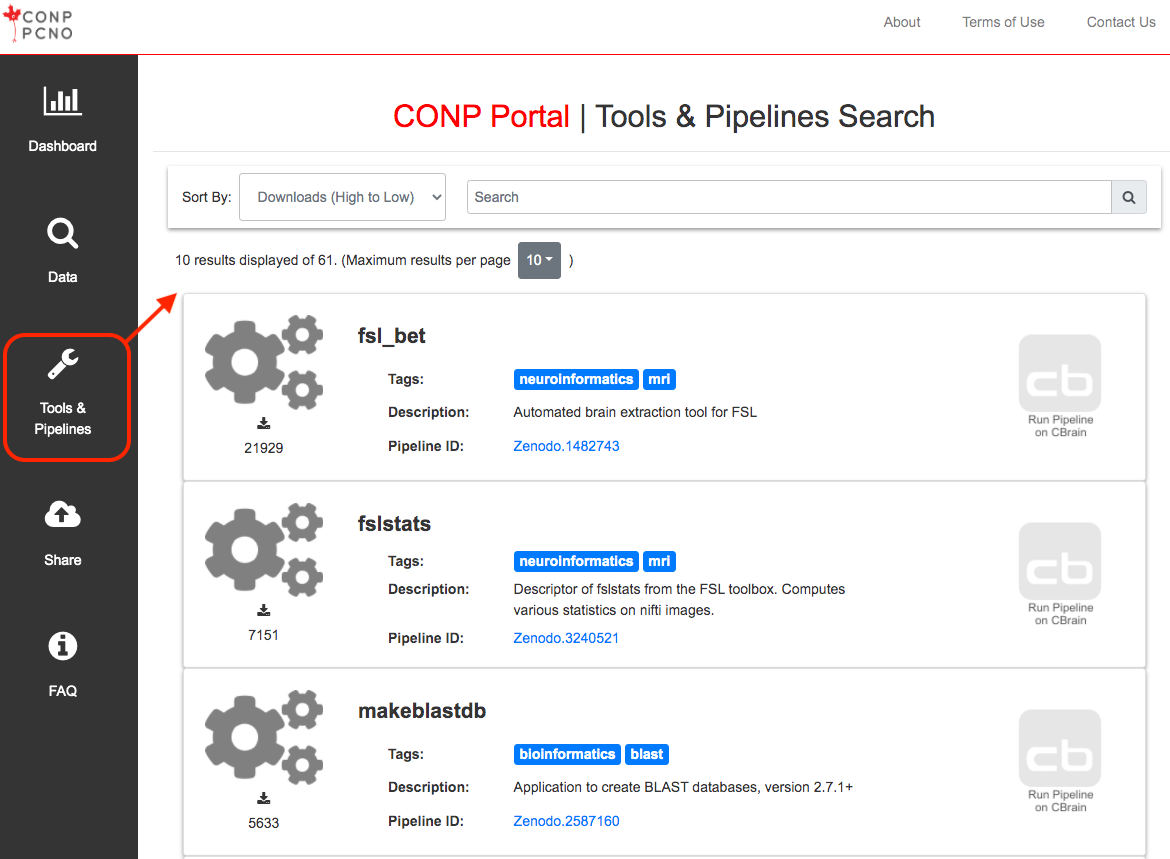
Finding tools/pipelines
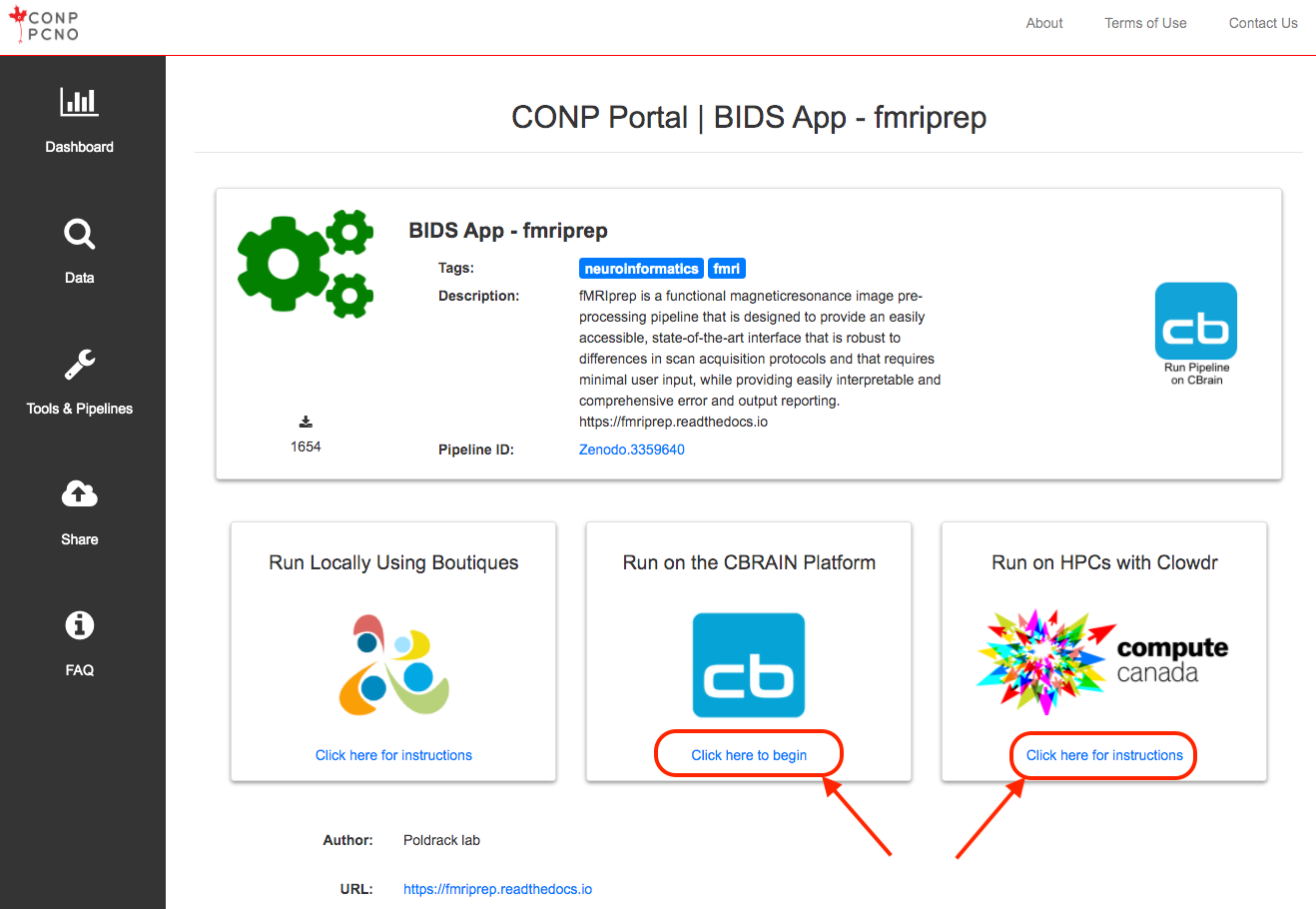
The Tools & Pipelines page lists all software registered in the Portal. Each tool or pipeline page contains basic information about the tool/pipeline and its pipeline/Zenodo ID.
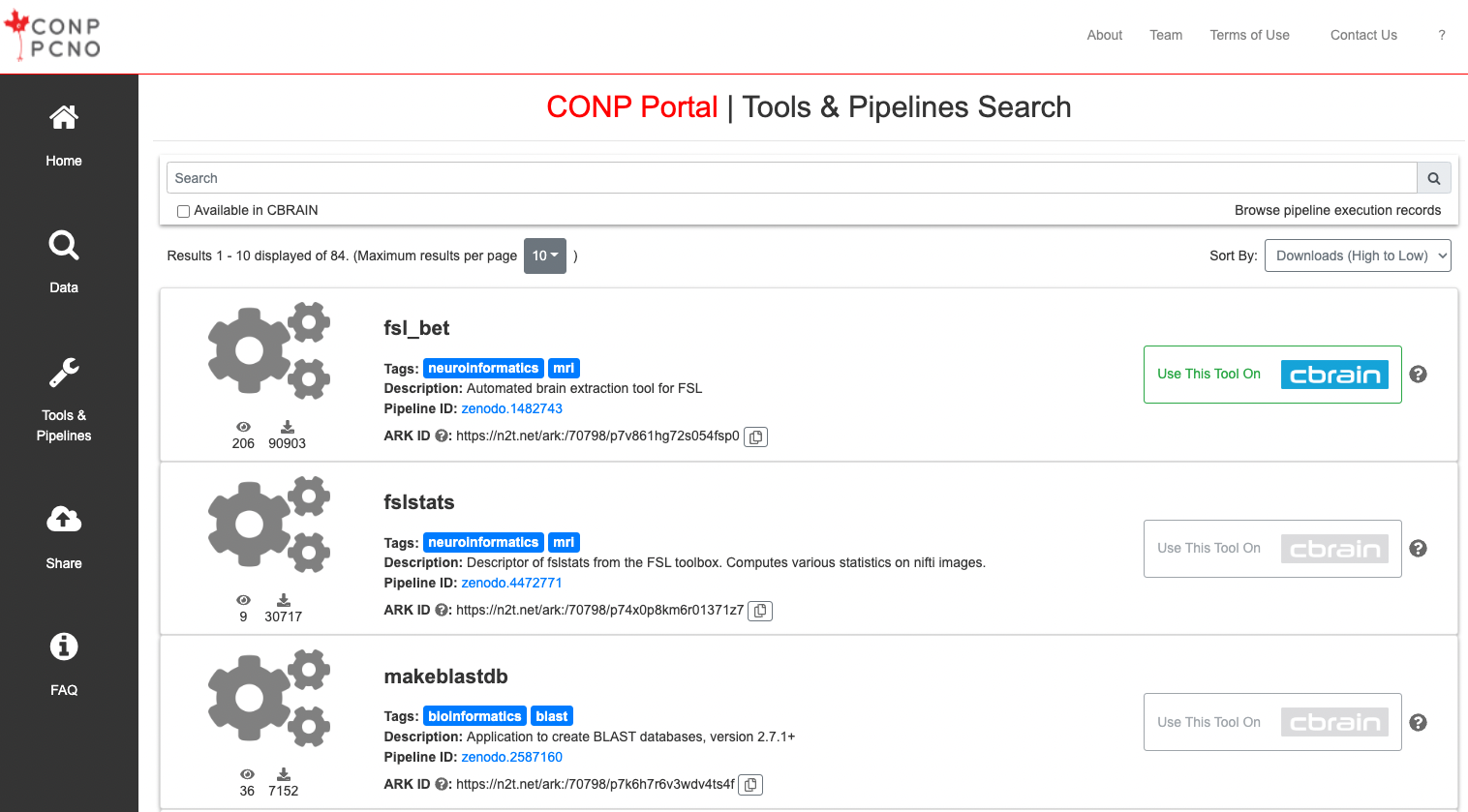
Clicking on a specific tool name from the list or search results will bring the user to a more detailed page with links to instructions on how to run the tool locally, on HCPs, or external platforms.
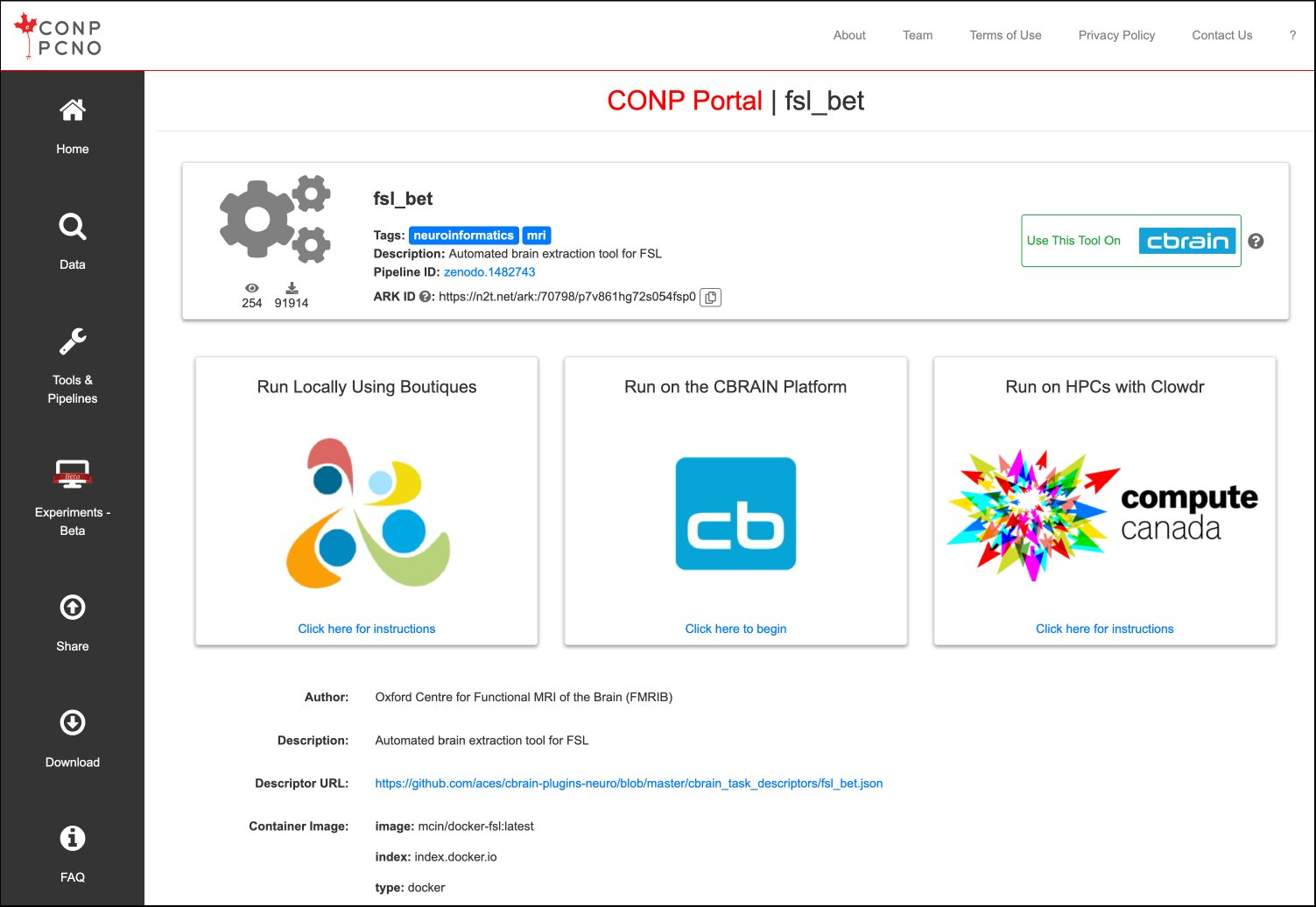
Running a tool/pipeline
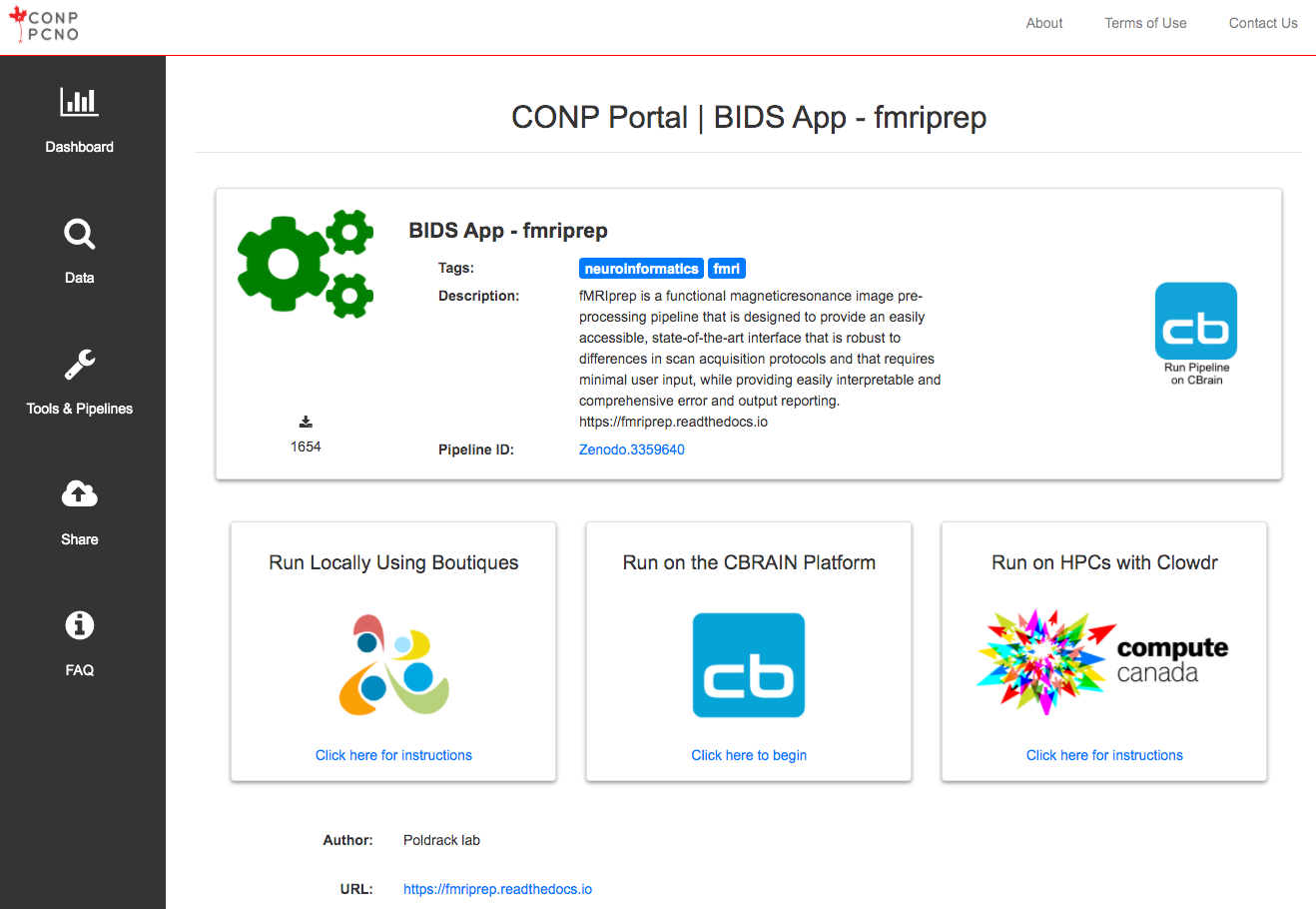
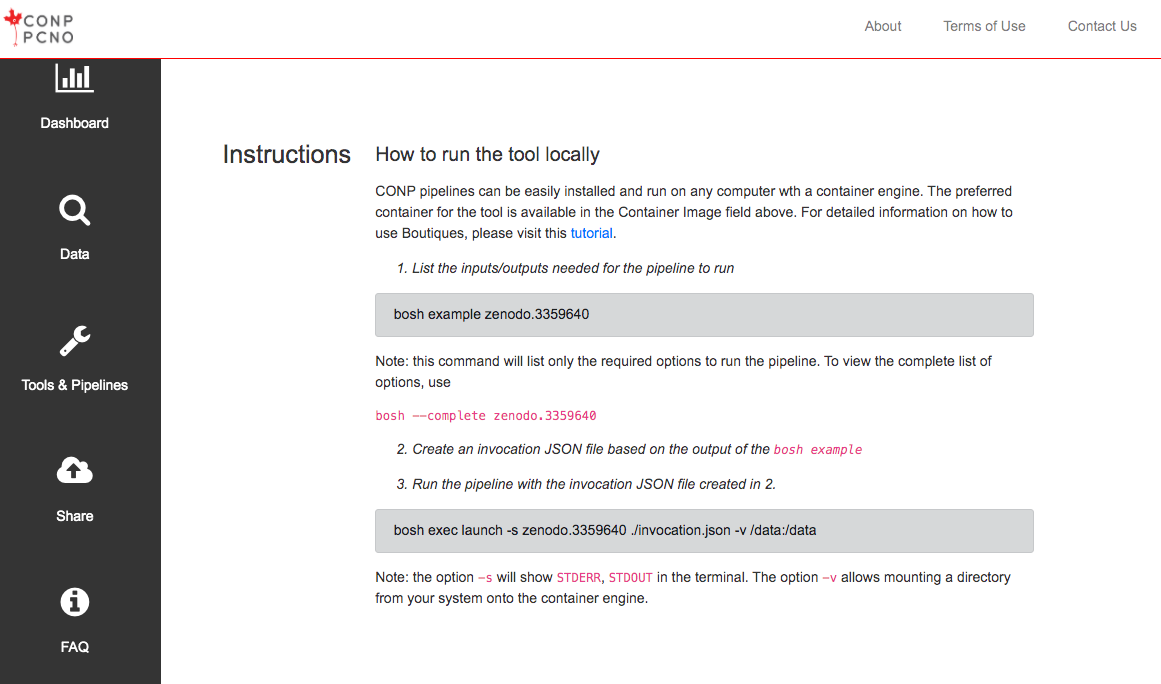
Run the tool locally
Tools and pipelines can be run locally on any system using Boutiques and a container engine (Docker or Singularity) based on the Zenodo ID of the tool, as described on the full page for each tool/pipeline.
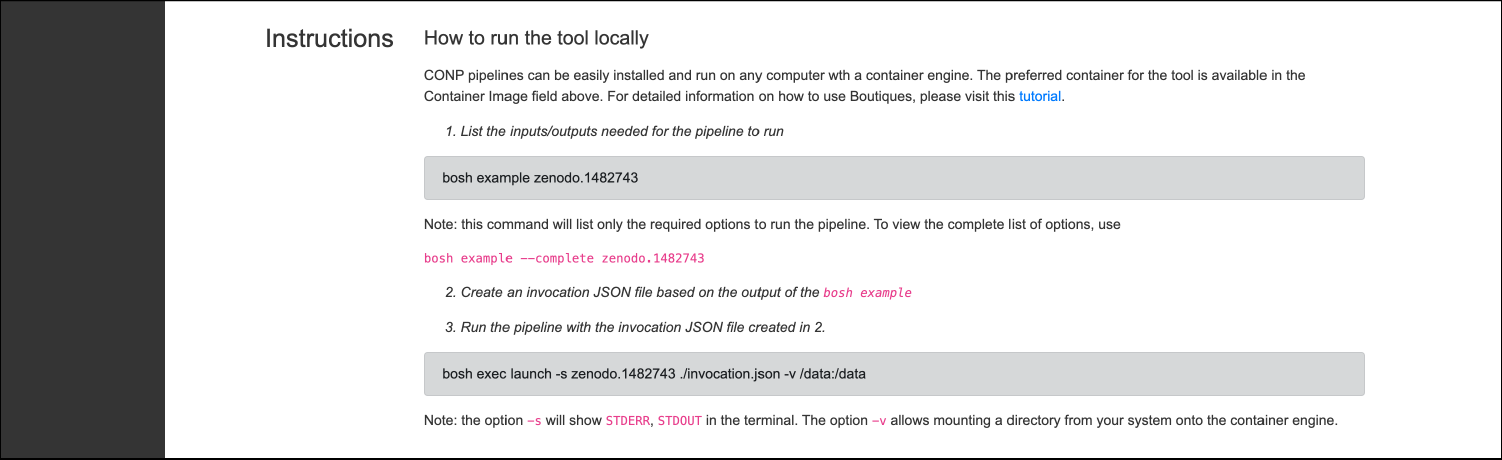
If you have never used Boutiques, we recommend the following tutorial.
Run the tool on HPCs
Some tools and pipelines can also be run on HPCs via the CBRAIN infrastructure or in your Digital Research Alliance of Canada account with Clowdr.

The "Click here to begin" link under the "Run on the CBRAIN Platform" container will open a tab to the login page of CBRAIN or to the tool page on CBRAIN if you are already logged in.
The "Click here for instructions" link under the "Run on HPCs with Clowdr" will open a new tab with the instructions on how to deploy a tool/pipeline on your Digital Research Alliance of Canada account.
Finding and downloading experiments (currently in a beta release)
Finding experiments
All experiments are listed in the Experiments search page of the CONP Portal, accessible by clicking on the "Experiments" button in the left-hand menu. This will take you to a search function that includes all metadata associated with experiments. You can also constrain the search with drop-down menus to filter by modality (e.g., fMRI), function assessed (e.g., cognition), software (e.g., PsychoPy).
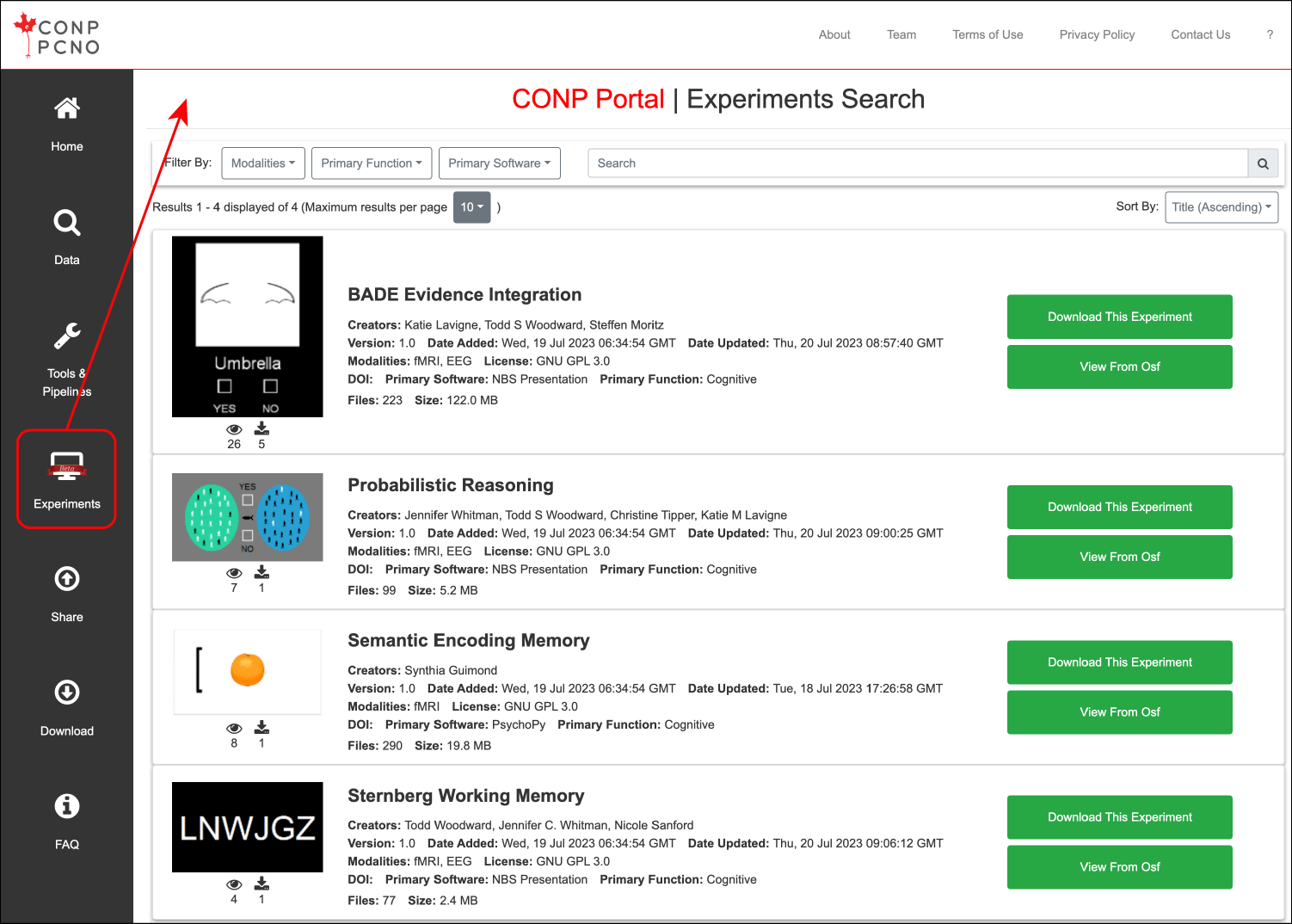
Downloading experiments
You can download the experiment directly from the search page or open its source page (e.g., on the OSF).
How can I upload my dataset?
Detailed instructions are available for different upload mechanisms on the Share page of the Portal.
How can I upload my tool/pipeline?
You can publish your tools/pipelines using Boutiques’ command bosh publish.
For more information on how to do that, please visit the ‘Publishing your own tool’ section of the Boutiques tutorial Python notebook.